From event-driven programming to FRP
The problem
Most of modern programming is based on events. Event-driven frameworks are the proven and true abstraction to express any kind of asynchronous and interactive behavior, like GUIs or client-server architectures.
The core idea is inversion of control: the main loop is run by the framework, users only have to register some form of “callbacks”, and the framework will take care of calling them at the appropriate times.
This solves many issues that a straightforward imperative/procedural approach would present, eliminates the need for any kind of polling, and creates all sorts of opportunities for general-purpose optimizations inside the framework, with no impact on the complexity of user code. All of this without introducing any concurrency.
There are drawbacks, however. Event-driven code is hideous to write in most languages, especially those lacking support for first class closures. More importantly, event-driven code is extremely hard to reason about. The very nature of this callback-based approach makes it impossible to use a functional style, and even the simplest of interactions requires some form of mutable state which has to be maintained across callback calls.
For example, suppose we want to write a little widget with a button. When the button is pressed, a GET request is performed to some HTTP URL, and the result is displayed in a message box. We need to implement a simple state machine whose graph will look somewhat like this:
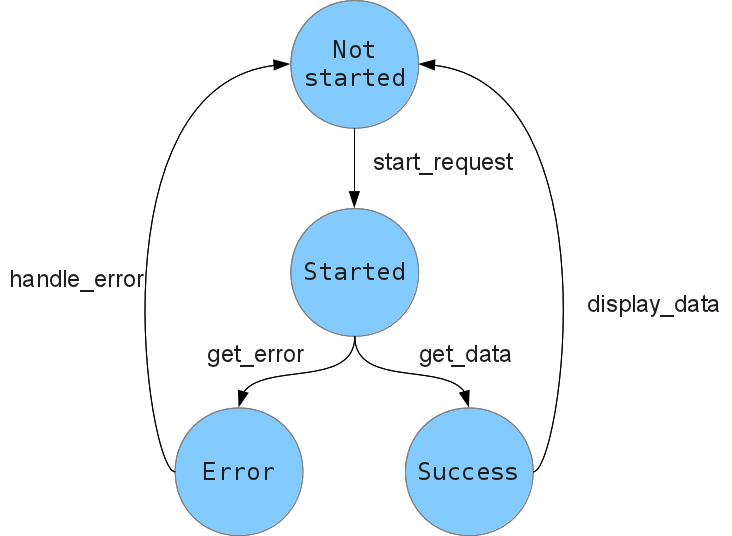
Each state (except the initial one) corresponds to a callback. The transitions are determined by the framework. To avoid starting more than one request at a time, we will need to explicitly keep track of the current state.
Now let’s try to make a simple change to our program: suppose we want to retry requests when they fail, but not more than once. Now the state machine becomes more complicated, since we need to add extra nodes for the non-fatal error condition.
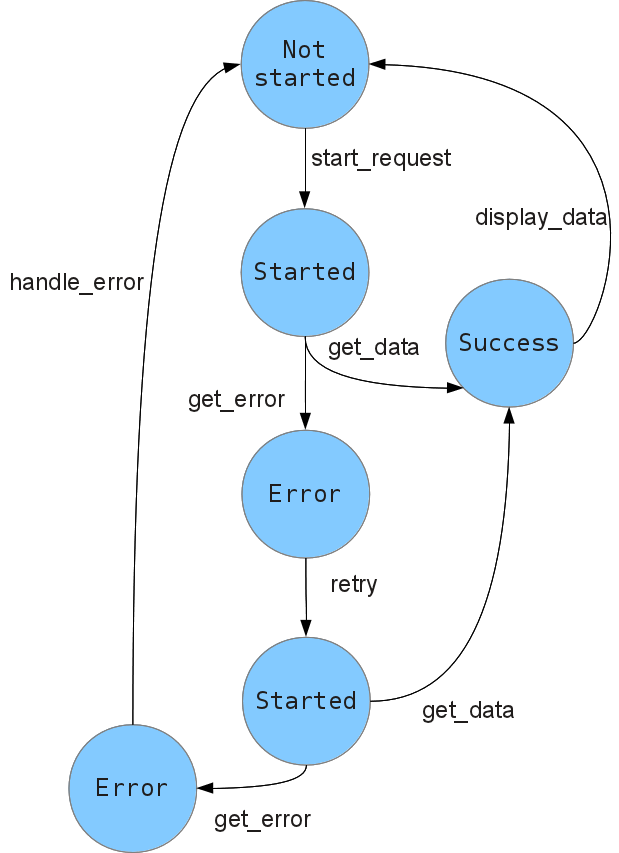
In our hypotetical event-driven code, we need to keep track of whether we already encountered an error, check this flag at each callback to perform the right action, and update it appropriately. Moreover, this time the code isn’t even shaped exactly like the state machine, because we reuse the same callback for multiple nodes. To test our code exhaustively, we need to trace every possible path through the graph and reproduce it.
Now assume we want to allow simultaneous requests… you get the idea. The code gets unwieldy pretty fast. Small changes in requirements have devastating consequences in terms of the state graph. In practice, what happens most of the times is that the state graph is kept implicit, which makes the code impossible to test reliably, and consequently impossible to modify.
Towards a solution
A very simple but effective solution can be found by observing that state graphs like those of the previous examples have a very clear interpretation within the operational semantics of the equivalent synchronous code.
A single forward transition from A to B can be simply modelled as the sequence A;B, i.e. execute A, then execute B. Extra outward transitions from a single node can be mapped to exceptions, while backward arrows can be thought of as looping constructs.
Our second state machine can then be translated to the following pseudopython:
while True: for i in xrange(2): error = None try: reply = start_request() data = get_data(reply) break except Exception as e: error = get_error(e) if error: handle_error(error) else: display_data(data)
This code is straightforward. It could be made cleaner by splitting it up in a couple of extra functions and removing the local state, but that’s beside the point. Note how easy it is now to generalize to an arbitrary number of retries.
So the key observation is that we can transform asynchronous code into synchronous-looking code, provided that we attach the correct semantics to sequencing of operations, exceptions and loops.
Now the question becomes: is it possible to do so?
We could turn functions like start_request and get_data into blocking operations that can throw. This will work locally, but it will break asynchronicity, so it’s not an option.
One way to salvage this transformation is to run the code in its own thread. Asynchronous operations will block, but won’t hang the main loop, and the rest of the program will continue execution.
However, we need to be careful with the kind of threads that we use. Since we don’t need (and don’t want!) to run multiple threads simultaneously, but we need to spawn a thread for each asynchronous operation, we have to make sure that the overhead is minimal, context switching is fast, and we’re not paying the cost of scheduling and synchronization.
Here you can find a sketched solution along these lines that I wrote in python. It’s based on the greenlet library, which provides cooperative multithreading.
In the next post I will talk about alternative solutions, as well as how to extend the idea further, and make event-driven more declarative and less procedural.
Comments